Les données manquantes sont les données qui ne sont pas présentes.
La donnée peut-être remplacée dans le tableau par :
NA
Une autre valeur dépendante des données ou de la personne qui s’en ai occupée : 0, NO, 999…
Note
Quelques soit le cas, il existent plusieurs origines aux données manquantes.
Type de données manquantes
Les données manquantes, représentées par NA ou autre peuvent avoir plusieurs origines :
La donnée n’est pas compatible. Par exemple, une personne rentre du texte au lieu d’un numéro de téléphone. Dans ce cas le système ne prends pas en charge la réponse et la qualifie en NA pour Not Applicable
La donnée n’existe pas. Par exemple la personne n’a pas de numéro de téléphone, dans ce cas, le système la qualifie de NA pour Not Available
La donnée existe mais n’a pas été communiquées. Par exemple la personne a refusé de donner son numéro, dans ce cas, le système la qualifie de NA pour Not Answer
Dans tous les cas, la seule information transmise est que la données n’est pas disponible.
Il n’est pas toujours possible de cerner l’origine du problème mais cela n’empêche pas d’agir.
Il faut commencer par se demander ce que signifie cette absence et comment elle va impacter notre système.
Conséquences des valeurs manquantes
Perte d’information : Si la donnée peut-être retrouvée ou remplacée, pourquoi s’en empêcher ?
Erreur dans la généralisation : Si beaucoup de données sont manquantes et que les conclusions se basent uniquement sur celles présentent, est-ce que cela représente vraiment la réalité ?
Comportement de certains modèles stats
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.0 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(missMDA)data("snorena")# régression logistique regression_logistique <-glm( snore ~ age + weight + size + alcohol, family = binomial, data = snorena )regression_logistique
Call: glm(formula = snore ~ age + weight + size + alcohol, family = binomial,
data = snorena)
Coefficients:
(Intercept) age weight size alcohol
-4.221694 0.061238 0.001180 -0.001735 0.157680
Degrees of Freedom: 72 Total (i.e. Null); 68 Residual
(27 observations effacées parce que manquantes)
Null Deviance: 93.83
Residual Deviance: 84.72 AIC: 94.72
summary(regression_logistique)
Call:
glm(formula = snore ~ age + weight + size + alcohol, family = binomial,
data = snorena)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.221694 6.845567 -0.617 0.5374
age 0.061238 0.025278 2.423 0.0154 *
weight 0.001180 0.040353 0.029 0.9767
size -0.001735 0.055573 -0.031 0.9751
alcohol 0.157680 0.080148 1.967 0.0491 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 93.828 on 72 degrees of freedom
Residual deviance: 84.724 on 68 degrees of freedom
(27 observations effacées parce que manquantes)
AIC: 94.724
Number of Fisher Scoring iterations: 4
regression_logistique_2 <-glm( snore ~ age + alcohol, family = binomial, data = snorena )AIC(regression_logistique, regression_logistique_2)
Warning in AIC.default(regression_logistique, regression_logistique_2): tous
les modèles n'ont pas été ajustés sur le même nombre d'observations
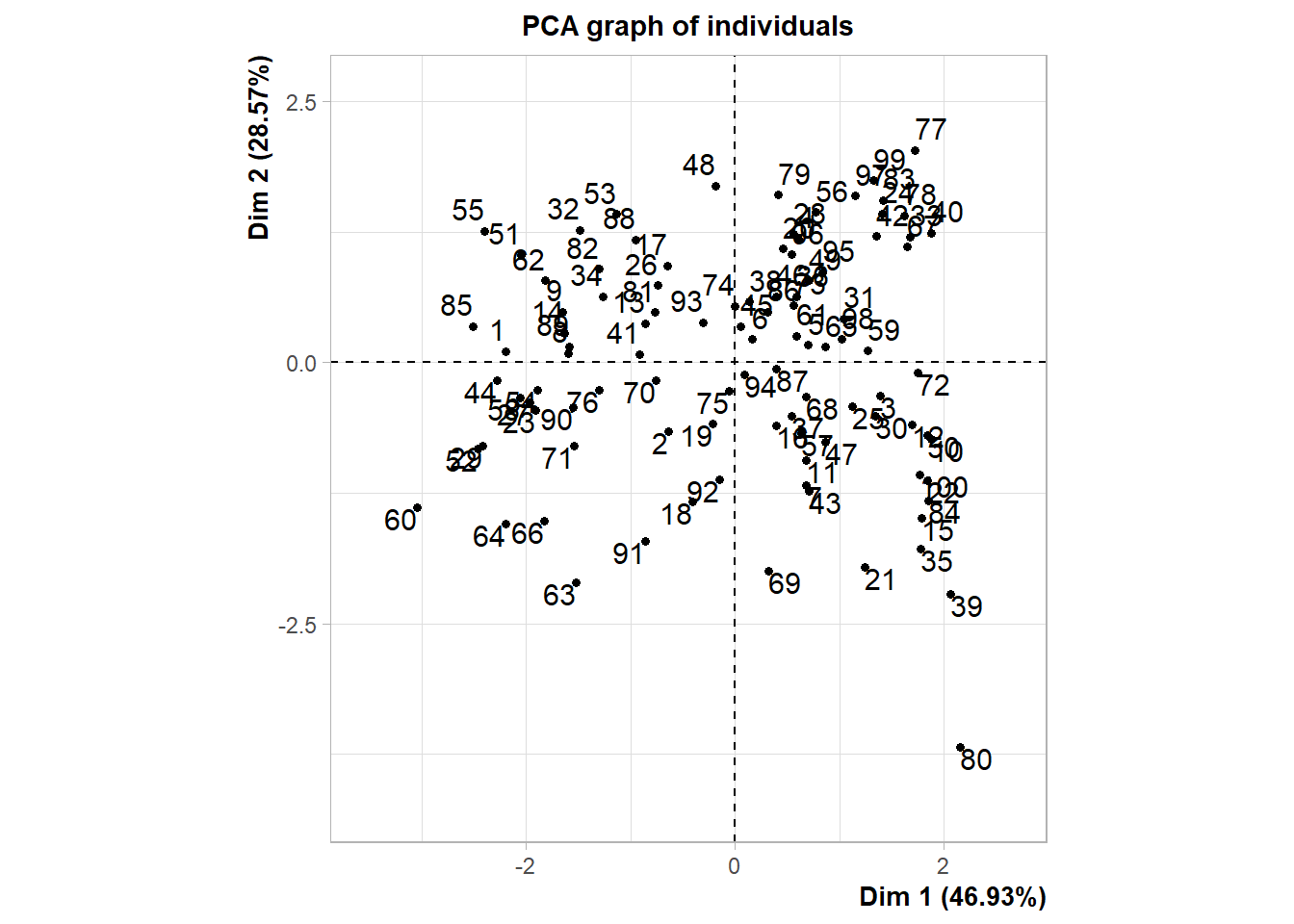
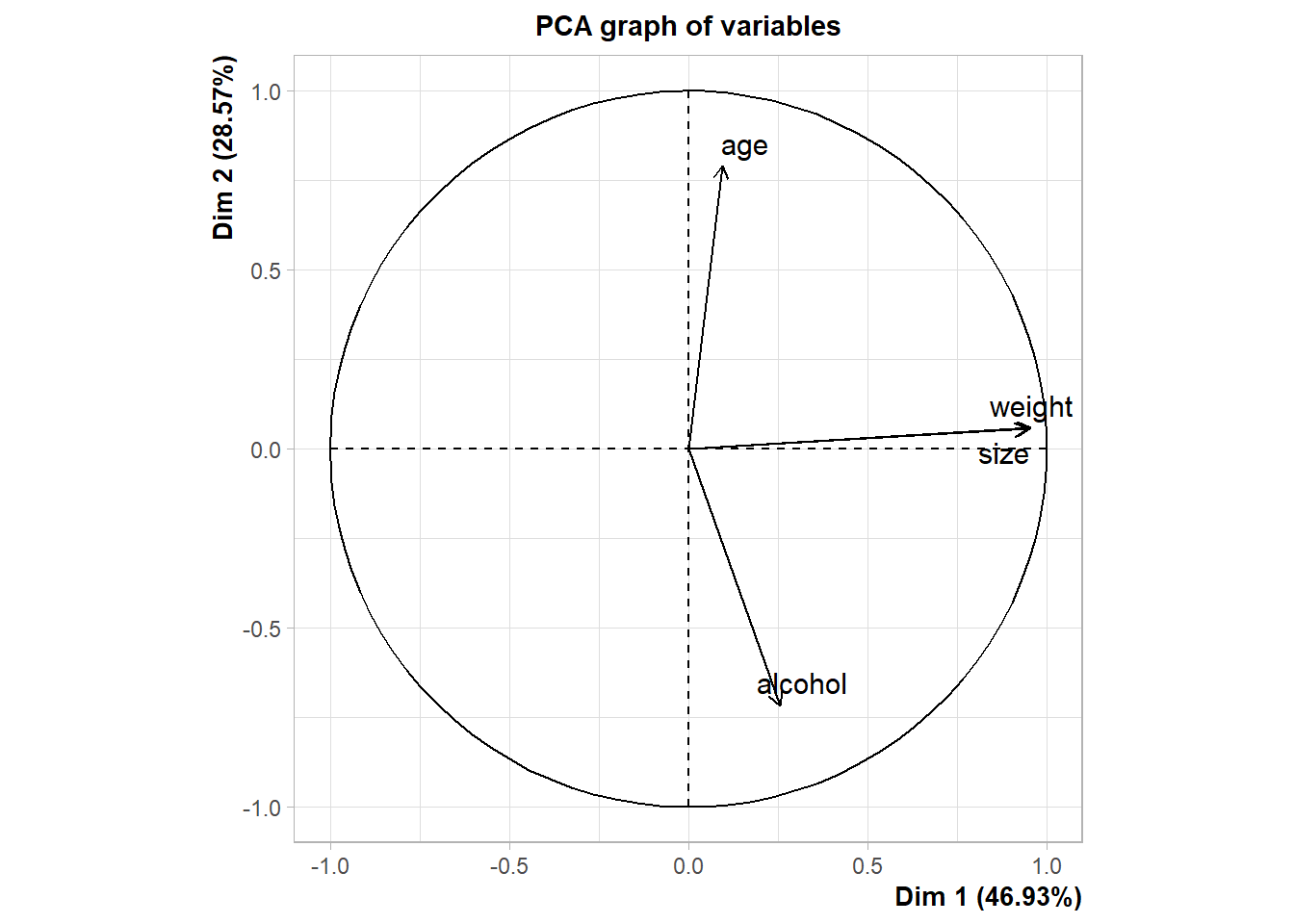
Warning in PCA(select(snorena, where(is.numeric))): Missing values are imputed
by the mean of the variable: you should use the imputePCA function of the
missMDA package
La régression logistique supprime les lignes avec les données manquantes alors que l’analyse en composantes principales les remplace par la moyenne de la colonne.
Il est donc important de garder en tête comment sont traités les données manquantes en fonction des statistiques utilisées.
Identifier les valeurs manquantes
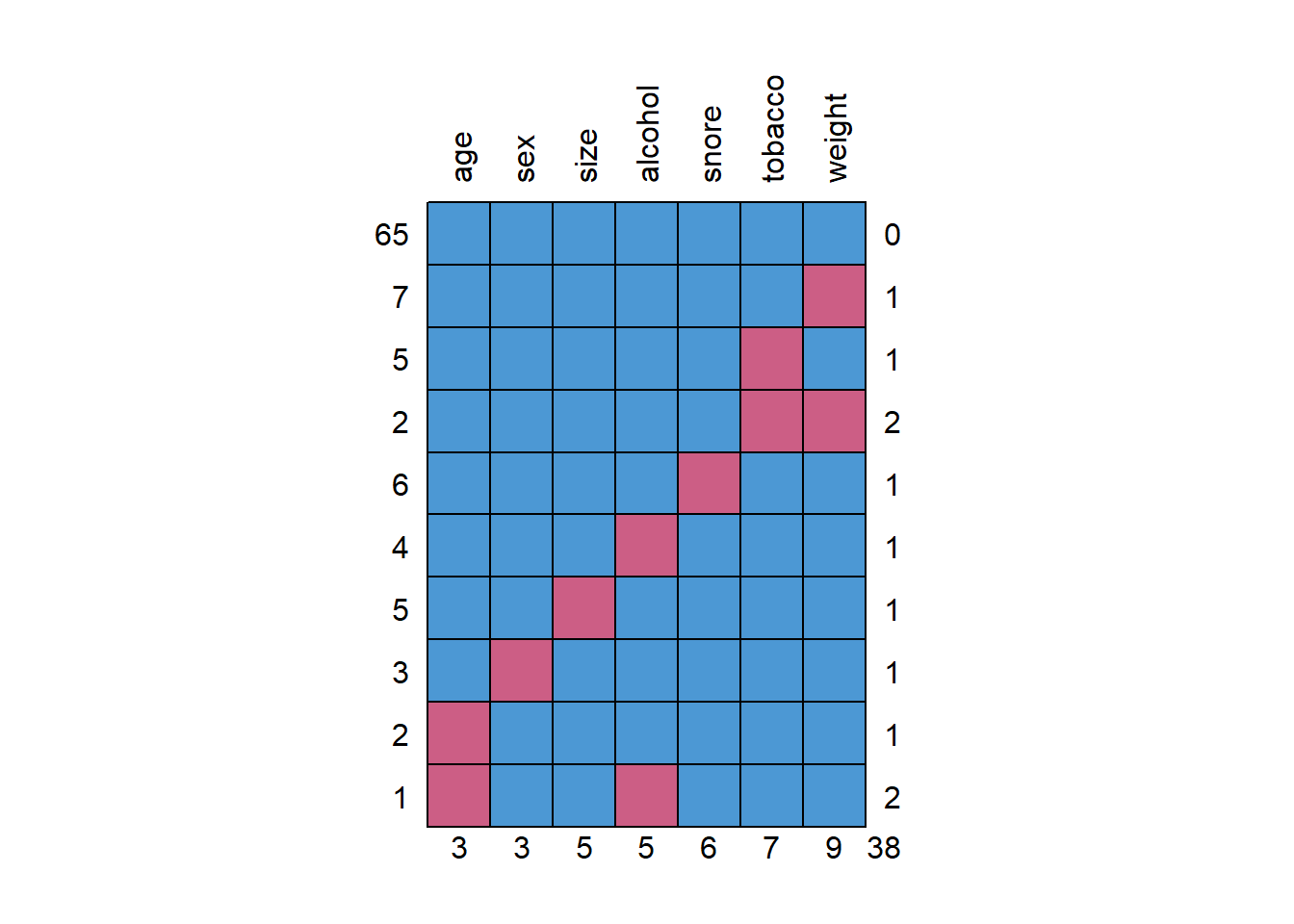
Pour savoir comment agir, il faut commencer par quantifier et localiser les valeurs manquantes.
Une réalisation simple est l’utilisation de la fonction summary() du package {base}.
summary(snorena)
age weight size alcohol sex
Min. :23.00 Min. : 42.0 Min. :158.0 Min. : 0.000 M :75
1st Qu.:43.00 1st Qu.: 77.0 1st Qu.:166.0 1st Qu.: 0.000 W :22
Median :51.00 Median : 94.0 Median :186.0 Median : 2.000 NA's: 3
Mean :52.16 Mean : 90.4 Mean :181.1 Mean : 2.905
3rd Qu.:63.00 3rd Qu.:104.5 3rd Qu.:194.0 3rd Qu.: 4.000
Max. :74.00 Max. :120.0 Max. :208.0 Max. :15.000
NA's :3 NA's :9 NA's :5 NA's :5
snore tobacco
N :62 N :32
Y :32 Y :61
NA's: 6 NA's: 7
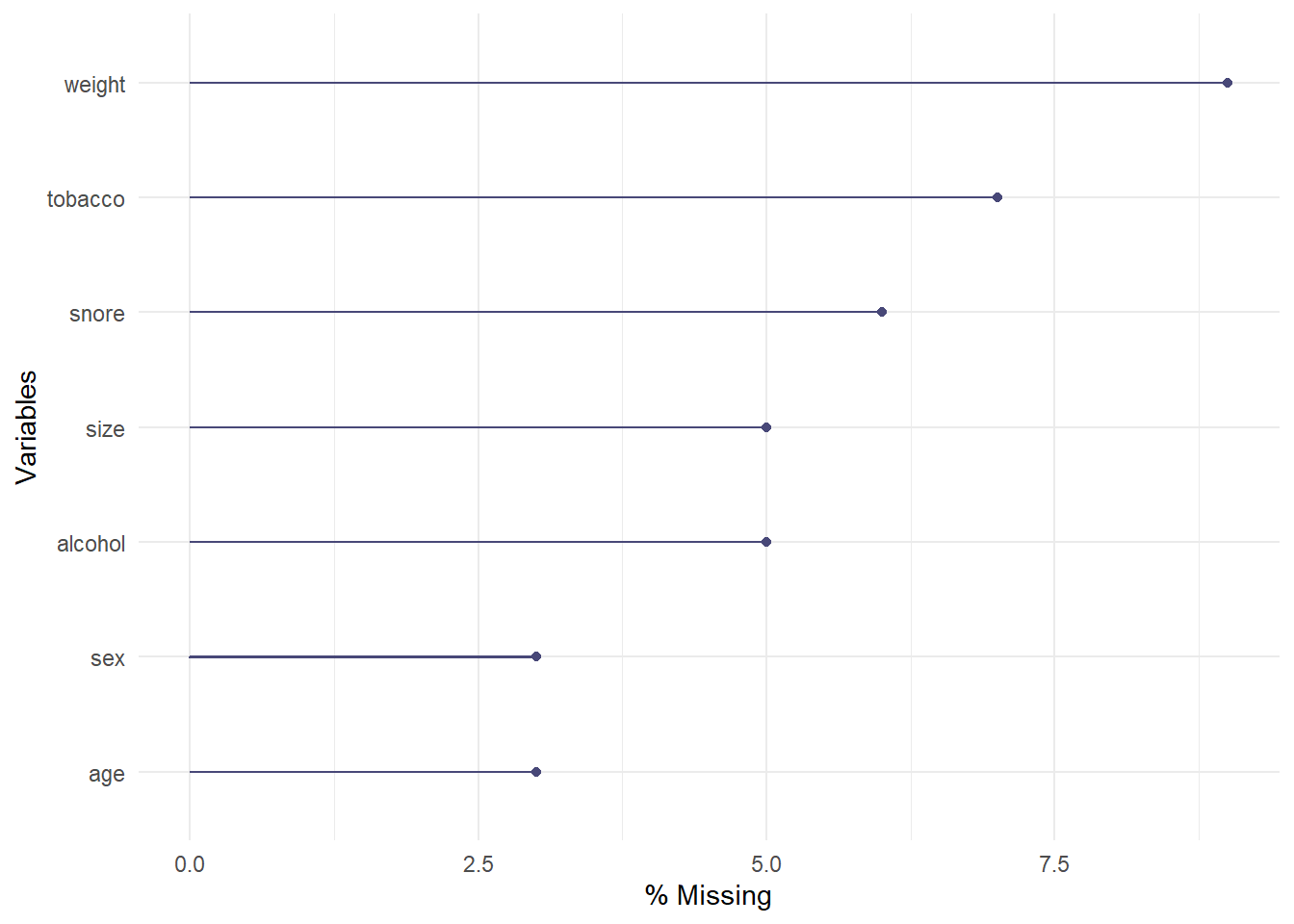
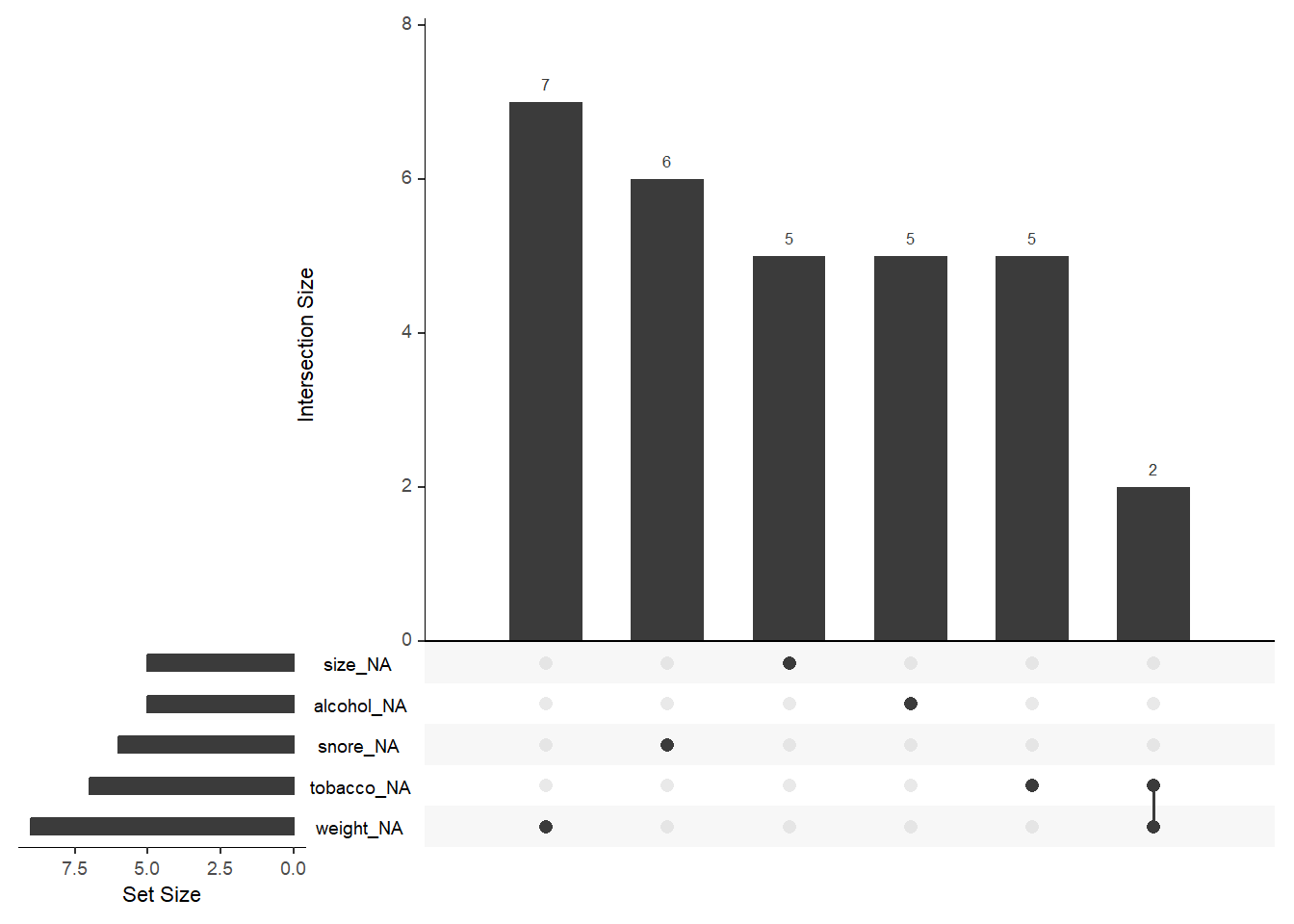
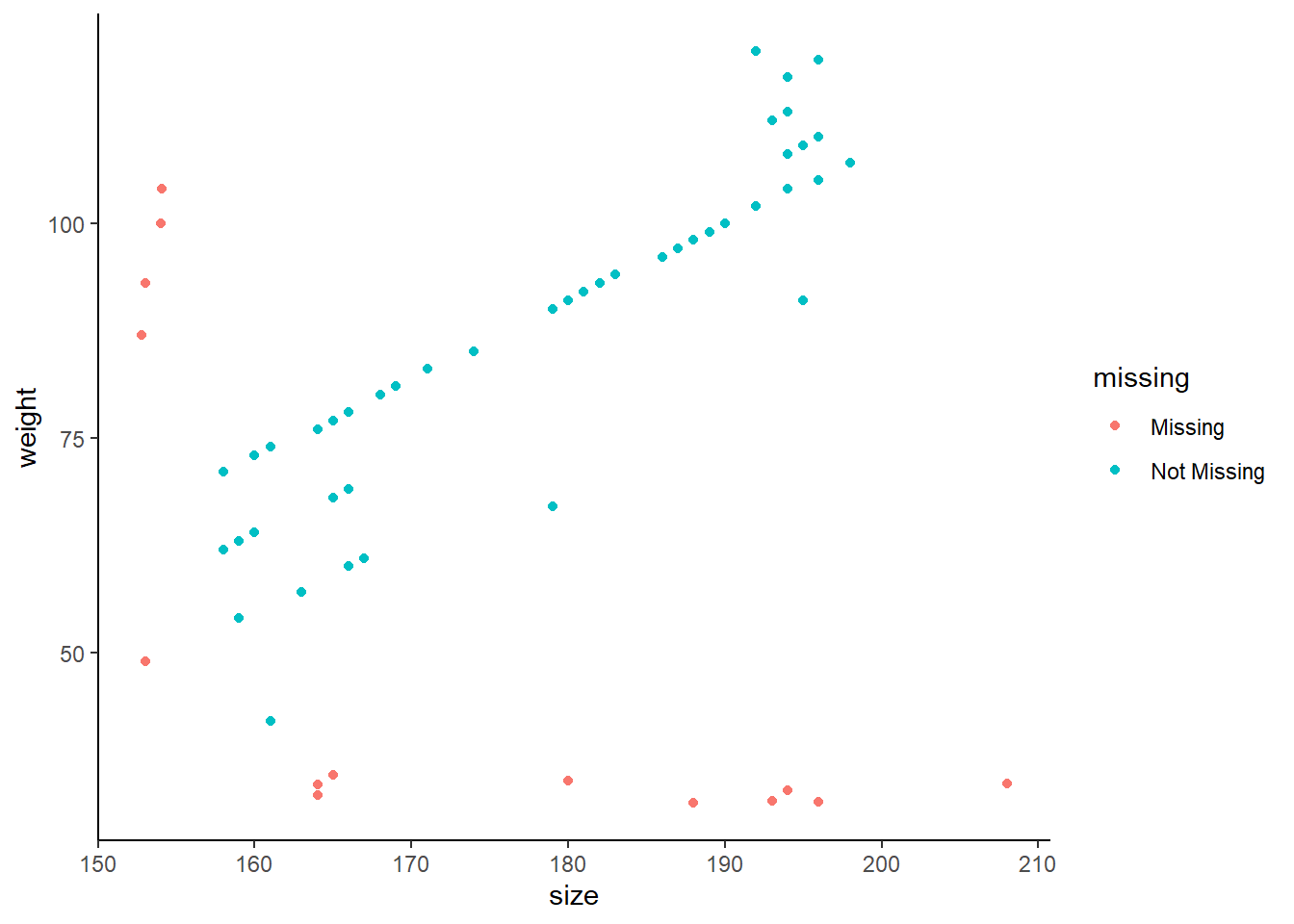
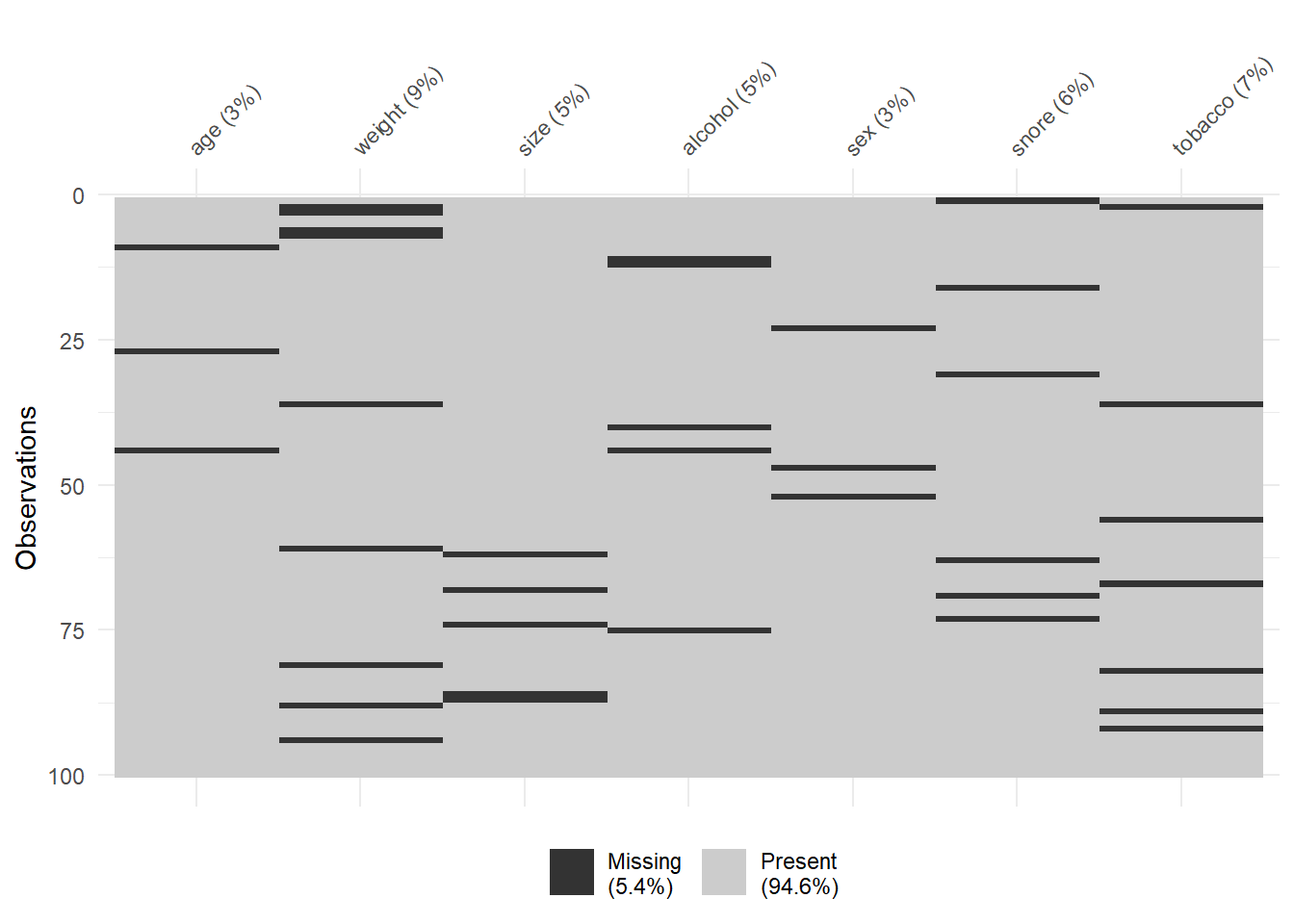
Le package {naniar} est spécialement adapté à la visualisation des données manquantes.
Visualisation du nombre (argument show_pct = FALSE) ou de la proportion (argument show_pct = TRUE) de données manquantes grâce aux fonctions gg_miss_var().
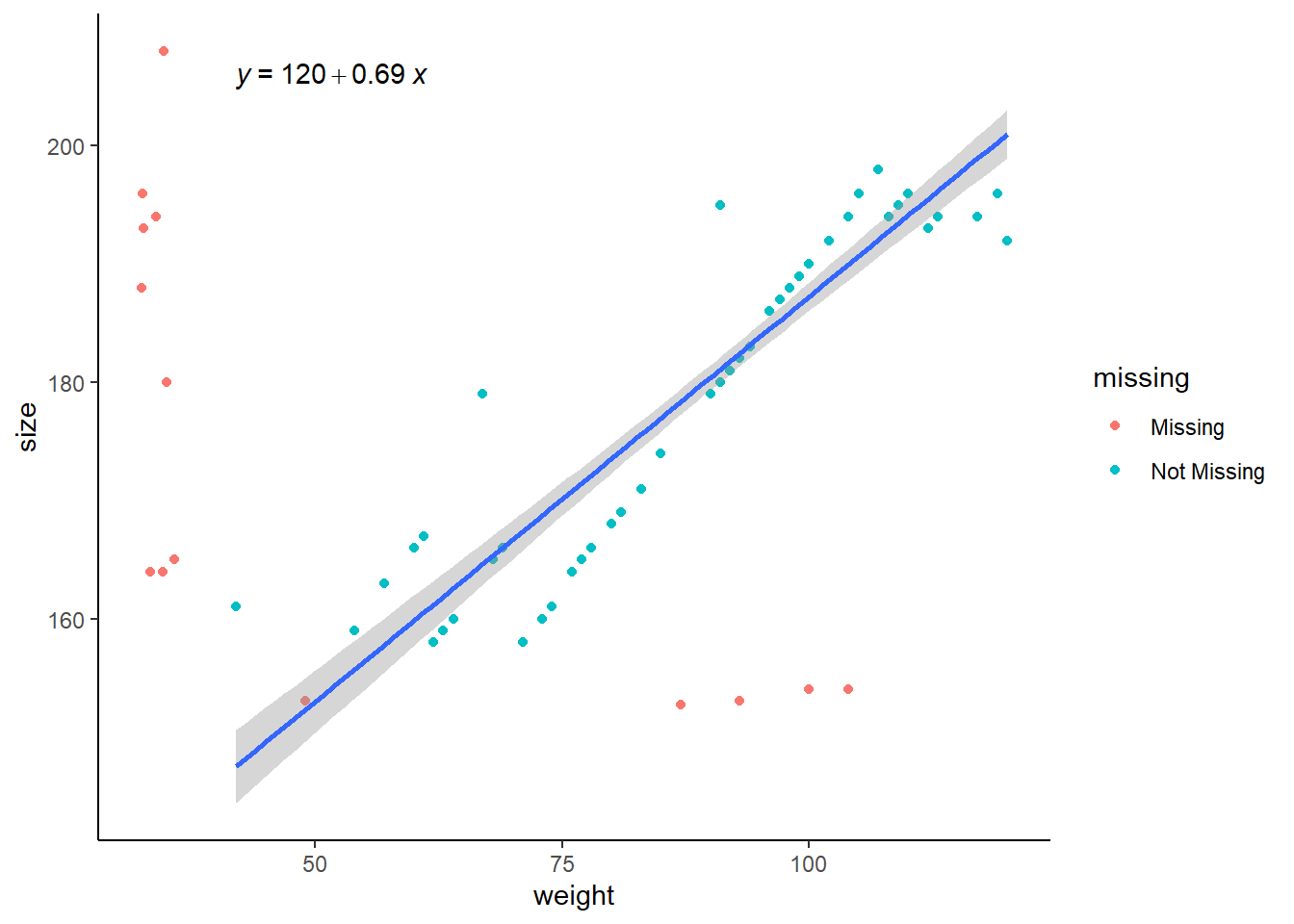
Les données manquantes peuvent avoir été remplacées par d’autres. Il est nécessaire de faite une analyse descriptive pour les détecter.
L’analyse descriptive
L’analyse descriptive a pour but d’analyser les variables pour connaître la nature des données mais aussi identifier les valeurs extrêmes (à ne pas confondre avec aberrantes).
La vraie valeur s’il est possible de la retrouver.
Une valeur de remplacement :
Déterminée à partir des autres données de la variables : moyenne, médiane, minimum, maximum…
Modélisée à partir des autres variables grâce à une régression linéaire, une ACP…
Ne pas remplacer la données mais garder le NA
Supprimer la ligne ou la colonne concernée. Cette solution est la moins envisageable et ne doit être mise en place que si les deux autres ne sont pas possibles.
age weight size alcohol sex
Min. :23.00 Min. : 42.0 Min. :158.0 Min. : 0.000 M :75
1st Qu.:43.00 1st Qu.: 77.0 1st Qu.:166.0 1st Qu.: 0.000 W :22
Median :51.00 Median : 94.0 Median :186.0 Median : 2.000 NA's: 3
Mean :52.16 Mean : 90.4 Mean :181.1 Mean : 2.905
3rd Qu.:63.00 3rd Qu.:104.5 3rd Qu.:194.0 3rd Qu.: 4.000
Max. :74.00 Max. :120.0 Max. :208.0 Max. :15.000
NA's :3 NA's :9 NA's :5 NA's :5
snore tobacco
N:68 N :32
Y:32 Y :61
NA's: 7
age weight size alcohol sex
Min. :23.00 Min. : 42.0 Min. :153.8 Min. : 0.000 M :75
1st Qu.:43.00 1st Qu.: 77.0 1st Qu.:166.0 1st Qu.: 0.000 W :22
Median :51.00 Median : 94.0 Median :186.0 Median : 2.000 NA's: 3
Mean :52.16 Mean : 90.4 Mean :181.0 Mean : 2.905
3rd Qu.:63.00 3rd Qu.:104.5 3rd Qu.:194.0 3rd Qu.: 4.000
Max. :74.00 Max. :120.0 Max. :208.0 Max. :15.000
NA's :3 NA's :9 NA's :5
snore tobacco
N:68 N :32
Y:32 Y :61
NA's: 7
# regression linéairereg_lin <-lm(weight ~ size, data = snorena)reg_lin$coefficients
age weight size alcohol sex
Min. :23.00 Min. : 42.00 Min. :153.8 Min. : 0.000 M :75
1st Qu.:43.00 1st Qu.: 77.00 1st Qu.:166.0 1st Qu.: 0.000 W :22
Median :51.00 Median : 95.00 Median :186.0 Median : 2.000 NA's: 3
Mean :52.16 Mean : 90.72 Mean :181.0 Mean : 2.905
3rd Qu.:63.00 3rd Qu.:106.17 3rd Qu.:194.0 3rd Qu.: 4.000
Max. :74.00 Max. :124.72 Max. :208.0 Max. :15.000
NA's :3 NA's :5
snore tobacco
N:68 N :32
Y:32 Y :61
NA's: 7