Le code est disponible sur GitHub au format pdf ou .qmd
Objectif du projet
L’idée est d’analyser les données des élections françaises grâce au {tidyverse}.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Tip{tidyvserse}
C’est un ensemble de packages R qui permettent de manipuler et représenter facilement les données.
Si tu n’utilises pas, n’hésites pas à regarder les articles précédents pour te former doucement aux différents packages que j’utilise ici 😊
Rows: 3162440 Columns: 25
── Column specification ────────────────────────────────────────────────────────
Delimiter: ";"
chr (11): id_election, id_brut_miom, code_departement, libelle_departement, ...
dbl (14): inscrits, abstentions, votants, blancs, nuls, exprimes, ratio_abst...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
NoteChoix de la fonction du package {readr}
Il existe plusieurs fonctions au sein du package {readr} qui permettent de lire des données en fonction du format d’enregistrement.
Ici, j’utilise la fonction read_delim() car elle me permet de paramétrer le séparateur de colonnes en point-virgule; (et non virgule,) sans modifier le séparateur de décimale (il reste en point.).
Modifier les données de votes
Je n’ai pas cherché à analyser l’intégralité des votes, mais seulement ceux des élections municipales.
Il faut donc aller chercher les informations contenues dans le nom des élections année_type d'élection_tour grâce au package {stringr}.
Pour utiliser un objet dans R, il faut l’indexer, c’est-à-dire l’associer à un nom.
Pour enregistrer une modification, il faut donc réassocier à son nom comme fait juste au dessus.
Grâce à la fonction count() du package {dplyr} il est possible de voir le nombre de bureaux de votes par commune.
votes |>count( code_commune, an, type_election, tour_election ) |>arrange(desc(n))
Comme les données sont sous le format : une ligne par bureau de votes et élections (l’année, le type et le tour), on recalcule à l’échelle de la commune grâce au package {dplyr}.
Cette modification n’a été faites que sur les données de votes municipaux grâce à la fonction filter() du même package.
`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by code_commune, code_departement,
libelle_commune, an, and tour_election.
ℹ Output is grouped by code_commune, code_departement, libelle_commune, and an.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(code_commune, code_departement, libelle_commune, an,
tour_election))` for per-operation grouping (`?dplyr::dplyr_by`) instead.
# A tibble: 2 × 2
tour_election n
<chr> <int>
1 1er tour 109105
2 2ème tour 13529
Données de recensement
J’ai commencé à m’intéresser à ces données car c’est la première année que les petites communes (< 1000 habitant.e.s) sont obligées d’avoir des listes paritaires.
Les données de recensements ne sont pas disponible en format csv, seulement en format .xlsx.
J’ai donc été obligé lors du live de les télécharger sur mon ordinateur pour pouvoir les utiliser.
pop <- readxl::read_excel("data/POPULATION_MUNICIPALE_COMMUNES_FRANCE.xlsx") |>filter( p23_pop <1000 )
Création de la colonne + de 1000 hab
Une fois les données de recencesement importées, il est possible de les utiliser pour créer une nouvelle colonne qui caractérise les communes de plus de 1 000 personnes grâce aux fonctions mutate() et case_when() du package {dplyr}.
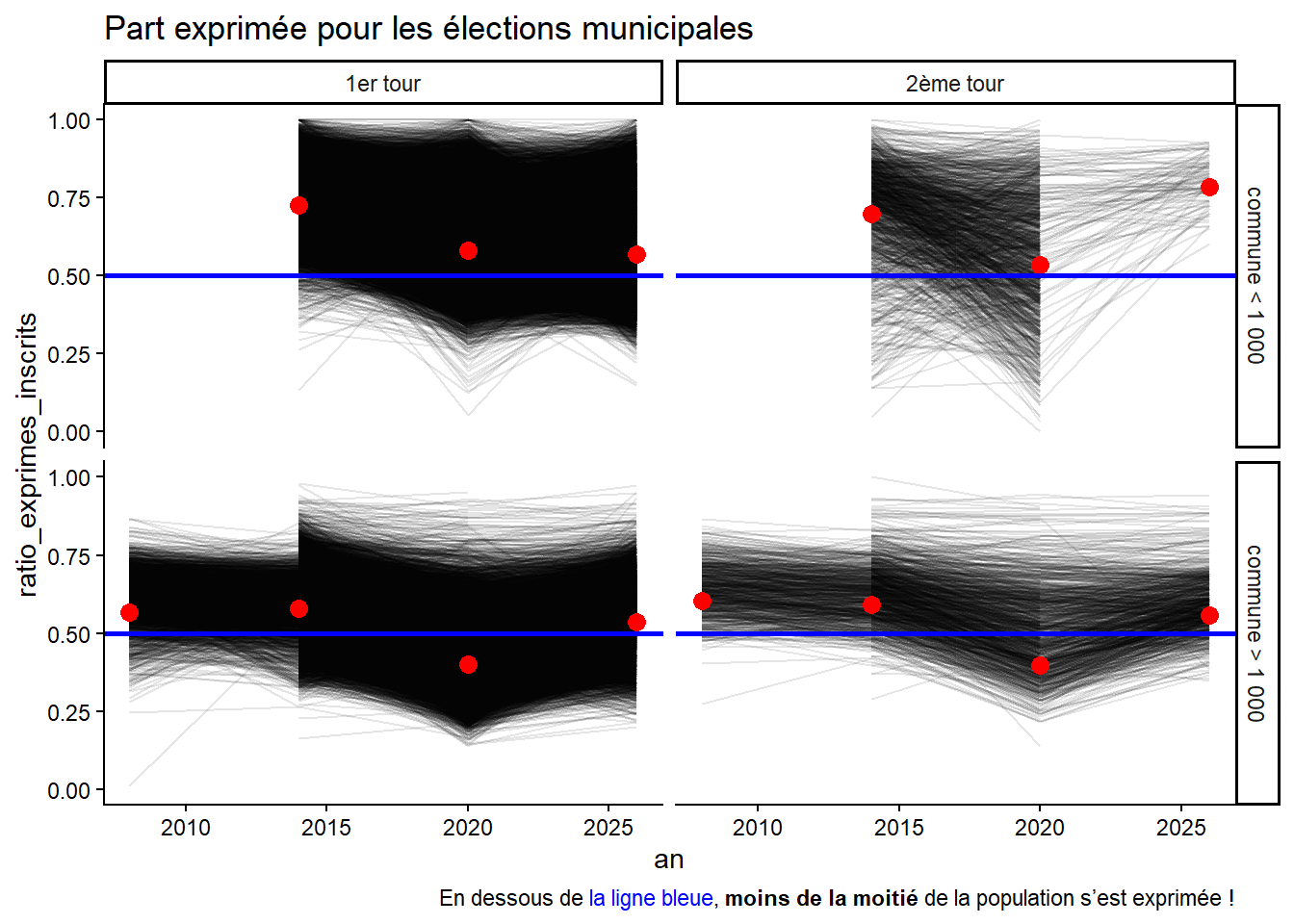
C’est le package {ggplot2} qui permet de représenter facilement en empilant les couches graphiques.
votes_municipaux_par_commune |>ggplot() +aes(x = an,y = ratio_exprimes_inscrits ) +geom_line(aes(group = code_commune), alpha =0.1) +geom_point(data = votes_municipaux_par_commune |>group_by(an, tour_election, commune) |>summarise(ratio_exprimes_inscrits =sum(nb_votes_exprimes)/sum(nb_pers_inscrites) ),size =3,color ="red" ) +geom_abline(aes(slope =0, intercept =0.5),color ="blue",size =1 ) +theme_classic() +theme(plot.caption = ggtext::element_markdown()) +facet_grid( commune ~ tour_election ) +labs(title ="Part exprimée pour les élections municipales",caption ="En dessous de <span style='color:blue;'>la ligne bleue</span>, **moins de la moitié** de la population s'est exprimée !" )
`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by an, tour_election, and commune.
ℹ Output is grouped by an and tour_election.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(an, tour_election, commune))` for per-operation
grouping (`?dplyr::dplyr_by`) instead.
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
TipUtiliser markdown avec {ggplot2}
Pour pouvoir utiliser la syntaxe markdown dans un graphique {ggplot2} il faut nécessairement installer le package {ggtext}.